INITCAP(char), LOWER(char), UPPER(char)
INITCAP함수는 매개변수로 들어오는 char의 첫 문자는 대문자로, 나머지는 소문자로 변환하는 함수입니다.
이때 첫 문자를 인식하는 기준은 공백과 알파벳(숫자 포함)을 제외한 문자입니다. 즉 공백이나 알파벳이 아닌 문자를 만난 후 다음 첫 알파벳 문자를 대문자로 변환합니다.
SELECT INITCAP('never say goodbye'), INITCAP('never6say*good가bye')
FROM DUAL결과 출력

LOWER 함수는 매개변수로 들어오는 문자를 모두 소문자로, UPPDER 함수는 대문자로 변환해 반환합니다.
SELECT LOWER('NEVER SAY GOODBYE'), UPPER('never say goodbye')
FROM DUAL결과 출력

CONCAT(char1, char2), SUBSTR(char, pos, len), SUBSTRB(charm pos, len)
CONCAT 함수는 '||' 연산자처럼 매개변수로 들어오는 두 분자를 붙여 반환합니다.
SELECT CONCAT('I Have', 'A Dream'), 'I Have' || 'A Dream'
FROM DUAL결과 출력

(개인적으로는 그냥 ||을 더 많이 쓸 거 같네요)
SUBSTR는 문자 함수 중 가장 많이 사용되는 함수로, 잘라올 대사 문자열인 char의 pos번째 문자부터 len 길이만큼 잘라낸 결과를 반환하는 함수입니다. pos값으로 0이 오면 디폴트 값인 1, 즉 첫 번째 문자를 가리키며, 음수가 오면 char 문자열 맨 끝에서 시작한 상대적 위치를 의미합니다.
또한 len 값이 생략되면 pos번째 문자부터 나머지 모든 문자를 반환합니다.
SELECT SUBSTR('ABCDEFG', 1, 4), SUBSTR('ABCDEFG', -1, 4)
FROM DUAL결과 출력 SUBSTR(음수, n)을하면 n이 어떤 값이 되던 오른쪽 맨 첫 번째 글자가 나옴

LTRIM(char, set), RERIM(char, set)
LTRIM 함수는 매개변수로 들어온 char 문자열에서 set으로 지정된 문자열을 왼쪽 끝에서 제거한 후 나머지 문자열을 반환합니다. 두 번째 매개변수인 set은 생략할 수 있으며, 디폴트로 공백 문자 한 글자가 사용됩니다.
RTRIM 함수는 LTRIM 함수와 반대로 오른쪽 끝에서 제거한 뒤 나머지 문자열을 반환한다.
SELECT
LTRIM('ABCDEFGABC', 'ABC'),
LTRIM ('가나다라', '가'),
RTRIM ('ABCDEFGABC', 'ABC'),
RTRIM ('가나다라', '가')
FROM DUAL결과 출력

LPAD(expr1, n. expr2), RPAD(expr1, n, expr2)
LPAD 함수는 매개변수로 들어온 expr2 문자열(생략할 때 디폴트는 공백 한 문자)을 n자리만큼 왼쪽부터 채워 expr1을 반환하는 함수입니다. 매개변수 n은 expr2와 expr1이 합쳐져 반환되는 총 자릿 수를 의미합니다.
예를 들면 서울의 지역 전화번호는 '02'인데 전화번호 칼럼에 지역번호가 없으면 LPAD함수로 번호 02를 자동으로 넣어줄 수 있습니다.
CREATE TABLE EX4_1 (
PHONE_NUM VARCHAR2(30));테이블 먼저 생성해주고
INSERT INTO EX4_1 VALUES ('111-1111');
INSERT INTO EX4_1 VALUES ('111-2222');
INSERT INTO EX4_1 VALUES ('111-3333');지역번호가 없는 전화번호를 넣어주고 확인
SELECT * FROM EX4_1;결과 출력
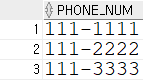
전화번호의 총자릿수는 8자리이고, 각 번호 앞에 (02)를 붙인다면 총 12자리가 됩니다.
SELECT LPAD(PHONE_NUM, 12, '(02)')
FROM EX4_1;결과 출력

만약 PHONE_NUM의 옆에 12라는 값을 넣지 않는다면 오류가 발생됩니다. '(02)'라는 문자열을 왼쪽에서부터 글자를 붙여야 하는데 크기가 10칸이면 '(0'만 붙어서 출력됩니다.

12를 빼고 결과 출력 시 - 숫자 지정을 해달라고 나옵니다.

RPAD는 LPAD와는 반대로 오른쪽에 해당 문자열을 채워 반환합니다.
SELECT RPAD(PHONE_NUM, 12, '(02)')
FROM EX4_1;결과 출력

REPLACE(char, search_str, replace_str), TRANSLATE(expr, from_str, to_str)
REPLACE 함수는 char 문자열에서 search_str 문자열을 찾아 이를 replace_str 문자열로 대체한 결과를 반환하는 함수입니다.
SELECT REPLACE('집에 가고 싶은데 아직 이르다', '집에', '헬스장')
FROM DUAL;결과를 출력해보면 '집에'와 '헬스장'이 바뀐 것을 알 수가 있습니다.

보통 문자열에서 공백을 제거할 때 LTRIM이나 RTRIM을 사용하지만 이 두 함수는 문자열 중간에 있는 공백을 제거하지 못합니다. 하지만 REPLACE 함수를 사용하면 문자열 네에 있는 모든 공백을 제거할 수 있습니다.
SELECT LTRIM(' ABC DEF '),
RTRIM(' ABC DEF '),
REPLACE(' ABC DEF ', ' ', '')
FROM DUAL;결과를 출력
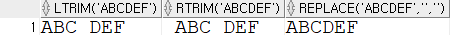
TRANSLATE 함수는 REPLACE와 유사하다. expr 문자열에서 from_str에 해당하는 문자를 찾아 to_str로 바꾼 결과를 반환하는데, REPLACE와 다른 점은 문자열 자체가 아닌 문자 한 글자씩 매핑해 바꾼 결과를 반환한다.
SELECT REPLACE ('나는 너를 싫어하는데 너는 나를 좋아하니?', '나는', '너를') AS rep,
TRANSLATE ('나는 너를 싫어하는데 너는 나를 좋아하니?', '나는', '너를') AS trn
FROM DUAL;결과를 출력해 보면

이런 결과가 나오는데 REPLACE와 TRANSLATE의 차이는 REPLACE는 왼쪽에 있는 '나는'만 '너를'로 변경하였는데
TRANSLATE는 글 안에 있는 모든 '나는'을 '너를'로 교체해버렸다. TRANSLATE 함수는 글자 한 자씩, 즉 '나'->'너', '는'->'를'로 변환해서 원래 문장에 있던 '는'이 모두 '를'로 바뀌어 맞춤법에 맞지 않는 문장이 되었습니다.
INSTR(str, substr, pos, occur), LENGTH(chr), LENGTH(chr)
INSTR함수는 str문자열에서 substr과 일치하는 위치를 반환하는데, pos는 시작 위치로 디폴트 값은
1. occur은 몇 번째 일치하는지를 명시하며 디폴트 값은 1입니다.
SELECT
INSTR('내가 만약 외로울 때면,내가 만약 괴로울 때면,내가 만약 즐거울 때면', '만약') AS INSTR1,
INSTR('내가 만약 외로울 때면, 내가 만약 괴로울 때면, 내가 만약 즐거울 때면', '만약', 5) AS INSTR2,
INSTR('내가 만약 외로울 때면, 내가 만약 괴로울 때면, 내가 만약 즐거울 때면', '만약', 5, 2) AS INSTR3
FROM DUAL;결과를 출력한 값이다.

1번은 처음 4번째 칸에 바로 있는 만약의 위치 값이 나오고
2번째는 만약 뒤에, 5를 붙여 줌으로써 5번째 글자부터 탐색하게 되어 18이 반환됩니다.
3번째는 occur 값이 2이므로 32가 반환되었습니다. (5번째 글자부터 2번째에 있는 만약을 찾음)
LENGTH 함수는 매개변수로 들어온 문자열의 개수를 반환하며, LENGTB 함수는 해당 문자열의 바이트 수를 반환합니다.
SELECT LENGTH('대한민국'),
LENGTHB('대한민국')
FROM DUAL;결과를 출력

LENGTH는 4개의 문자열의 개수를 찾았고 LENGTHB는 유티 코드 변환 시 한글은 2~3바이트를 소모하여 12를 반환하였습니다.